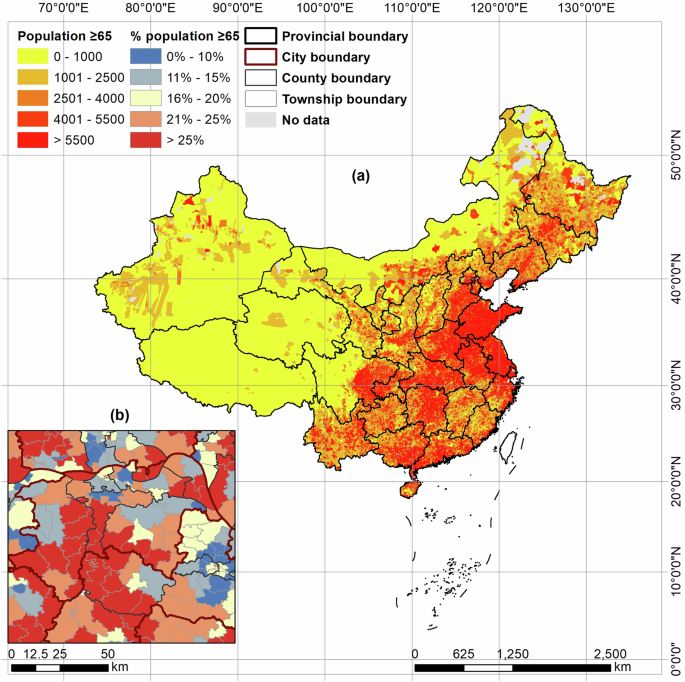
空间明确的人口分布数据在理解人类与环境互动方面至关重要,这些数据为环境健康、灾害管理、城市生态以及种族隔离等下游研究提供了重要基础。
尤其是由于儿童和老年人通常被视为易受损害的人群,包含年龄结构的空间明确人口数据在研究应用中显得尤为珍贵。
以往的研究通常利用按普查单位整理的人口数据来绘制人口分布图。例如,有研究表明,老年人比例较高的美国普查块组面临更高的因海平面上升而导致的洪水风险。
然而,普查单位的规模各异,可能包含大量无人区,并假设在给定单位内的人口均匀分布,这在现实中很少成立。
这些限制给有效建模人口空间分布和不同地理区域之间的比较带来了挑战。因此,一些研究进一步采用细化到更高分辨率的格网人口数据集,以精确描绘普查单位内的人口分布。
例如,Alegana等人在尼日利亚估计了1 × 1千米格网单元中五岁以下儿童的比重。他们发现,考虑到年龄结构的细微空间变化,而不是在普查单位内假设其均匀分布,可以在健康指标的估计上导致显著差异。
这些案例凸显了拥有高空间分辨率的空间明确人口数据集的重要性。
在一些发达经济体,如美国和加拿大,细分分辨率的人口数据相对更容易获取,而在发展中国家,如中国,则面临着不理想的数据可获取性。
与美国普查和美国社区调查提供通过块、区块组、地区、县和州等层级空间单位组织的数据相比,中国普查数据的层级结构也类似,但更粗糙,最精细的空间单位为镇。
使用镇一级的中国普查数据的另一个挑战是缺乏及时更新的镇级地理边界,这使得对数据进行地理编码变得困难。据我们所知,最新的公开镇级边界数据反映的是2019年的状况,然而,由于镇边界的更改和名称的变更,2019年的镇边界与2020年普查数据之间存在不匹配。
国民委员会的数据显示,中国有768个镇经历了边界变化,主要表现为合并和拆分为新镇。
更新这些边界是一个耗时但必要的步骤,以便正确进行2020年普查数据的地理编码。
研究人员还 resorted to gridded population datasets such as WorldPop and LandScan,这些数据集采用了朴素映射方法将人口计数从普查单位(源区域)分解到更细分的网格单元(目标区域)。
辅助数据与人口分布相关且具有高空间分辨率的数据用于此分解,通常包括道路、土地覆盖、建筑结构、地形、海拔、夜间光强和水体的分布,空间分辨率甚至可以细化到低于100米。
回归模型用于在普查单位层面建模人口计数与辅助数据变量之间的关系。
然后,将模型应用于格式化的辅助数据,以预测每个网格单元的人口计数。
在中国,现有的网格人口数据集通常是由过时的源人口数据分解而来。此外,县(在城市地区称为区)通常作为源区域使用,其粗糙的空间分辨率可能影响网格人口数据集的质量。
例如,广泛使用的WorldPop(版本2000–2020)提供每年2000年至2020年的总人口和按年龄组、性别的人口数据,其空间分辨率为100米。
具体而言,WorldPop(版本2000–2020)使用了2010年中国普查的镇级数据来估计网格总人口,并使用县级普查数据来估计按年龄组划分的网格人口数据。
对在县一级的增长率进行了应用,用于计划出后续年度的人口增长。这种新华社,仅仅县的粗糙分辨率可能无法捕捉到县和镇一级更细微的人口变化。
WorldPop(版本2015–2030,发布R2024B V1)的更新预计会整合2020年普查更近来的县级数据。虽然仍依赖于县级人口数据,但这一更新可以帮助解决WorldPop(2000–2020)中的总人口和年龄组估计因过旧的普查数据和县级增长率造成的某些不准确性。
其他一些关于中国的人口数据集也使用县级数据作为源区以生成他们的网格人口估算。
尽管加入时间上更为复杂,但镇级数据能够更好地反映中国的人口空间变化。
近期一项数据集PopSE,代表了首次利用2020年普查镇一级人口数据来估算网格级人口密度的努力。
然而,特定年龄组的网格级人口密度,来自2020年普查且对于分析脆弱群体的暴露很重要,仍然是必要的。
为了提高源数据的分辨率和时效性,我们开发了100米分辨率的基于2020年中国镇级人口普查的年龄分层人口估算(ASPECT)。
ASPECT的主要优势在于,首先,我们使用了来自40,718个镇的2020年普查人口数据,用以训练我们的随机森林模型进行朴素映射。
其次,除了总人口,ASPECT还估计了按年龄组(0–14岁,15–59岁,60–64岁,≥65岁)划分的人口。
这些附加信息能够为环境风险暴露和公共服务获取进行年龄组特定的估计。
我们采用了与先前研究类似的朴素映射方法生成ASPECT。
具体而言,我们收集了一系列与人口分布相关的协变量。
这些协变量的数据形式为100米分辨率的格网单元,然后以镇级进行汇总。
利用镇级数据,我们训练随机森林模型,将人口计数与协变量进行回归。
接下来,我们将该模型应用于格式化的协变量,从而生成一个人口加权层,以此将镇级人口分配至每个网格单元。
值得注意的是,我们为每个年龄组(即总人口,年龄组0–14岁,年龄组15–59岁,年龄组60–64岁和年龄组65岁及以上)分别训练了随机森林回归模型,并分别进行后续的人口加权过程。
我们执行了三组验证以评估ASPECT的质量。
首先,我们评估了镇级回归模型的拟合优度。
然后对每个网格单元,我们检查估计的总人口是否等于按年龄组估算的人口之和,因为这些数据是通过独立的朴素映射过程估算得出的。
最后,我们使用县级数据执行了朴素映射,该数据是比镇级粗一层的行政级别。
我们根据这些县级数据汇总了网格人口估计与实际镇级值进行比较。
这种比较可以帮助验证朴素映射的有效性,假设当使用镇级数据进行估计时,将能够获得更高的准确性。
我们还提供了与现有数据集的比较,包括WorldPop版本2000–2020(最新发布),WorldPop版本2015–2030(正在更新,发布R2024B V1)和Chen等人提出的PopSE。
我们从2020年中国人口普查中收集的镇级人口数据,测量截至2020年11月1日的居住人口,提供了总人口以及0–14岁、15–59岁、≥60岁和≥65岁年龄组家庭的信息。
每个镇的名称以及其上级行政单位的名称(县、市、省)也被提供,我们用来通过百度地图地理编码API获取每个镇的点位(经纬度坐标)。
我们进一步收集了镇级的行政边界并将其与2020年普查数据相对应。
我们获得了由国家公共地理信息服务平台发布的一个版本的镇边界。
根据我们的观察,这些边界可能还是反映2019年的状况。
然而,根据国家民政部的分发,某些镇之间的边界在这些年之间发生了变化。因此,我们手动更新了2019年的镇边界,以与2020年的普查数据进行匹配。
具体而言,我们首先识别了39326个镇及其名称和位置在2020年普查(包括点位)及2019年镇边界中匹配的169674个割接点。
在这些镇中,有36550个镇认为没有边界变化,2776个镇合并了其他镇。我们通过交叉参考政府公告、公开地图文档和其他边界数据集,编辑了剩余未匹配的镇边界。
我们编辑包括更新镇的名称、重新绘制边界和修正不正确的普查地理编码,确保更新后的镇边界与普查数据的地理表现相一致。
重要的是,这些编辑仅限于行政边界和普查地理编码,不会改变普查数据中的人口数量。
在这些编辑后,我们得到了1392个配合匹配2020年普查数据的额外镇。
在这些镇中,有745个镇的行政边界得到了修改,647个保持原来的界限。
覆盖边界变化的镇占了中国大陆总面积的502,418平方公里(约占5.16%)。
590个镇在2019年镇边界数据集中与任何2020年普查数据未能匹配。
这些镇的名称中通常包含国有农场、林场和工业园区等关键词,可能没有居住人口。
我们将这些镇视为2020年普查的缺失数据。
更新后的镇边界与2020年普查数据的插图显示,该研究区域人口数据几乎完全覆盖。
接下来的步骤中,我们收集可以预测人口分布的协变量的数据。
这些协变量包括建筑面积比例、建筑高度、夜间光强、距离道路的距离、兴趣点(POI)的密度、地形和水体,定义和数据源见于表1。
我们计算了每个格网单元的协变量值,然后将它们汇总到镇级。这些聚合后的协变量成为后续分析的输入。
与Chen等相比,我们利用这些纠正的协变量生成一个居住区掩膜,以提高网格化人口估计的质量。
一个居住区应具有大于零的建筑面积比例或建筑高度,且不得被任何水体覆盖。
我们仅在居住区内进行朴素映射,并将居住区外估算的人口视为零。
我们首先训练了一系列随机森林模型以测量镇级人口密度和协变量的关系。
模型分别针对总人口和不同年龄组(0–14岁、15–59岁、≥60岁和≥65岁)的构建,有效捕捉到协变量的差异效应。
人口密度由镇级人口除以居住区面积计算。
我们使用随机森林模型,遵循先前的文献,允许灵活建模人口密度和协变量之间的非线性关系。
值得注意的是,我们没有对人口密度进行对数变换,虽然以往文献中进行了这种变换。
对数变换将压缩人口密集的镇的回归误差,这可能使得协变量对镇级人口密度的预测变得更复杂。
我们通过使用在99%的中间区域分布的镇作为候选集来进行模型的调优。
训练样本包含候选镇的85%,而测试样本包含剩余的15%。
我们通过网格搜索交叉验证方法来调优模型,逐步训练随机森林模型,对每个独特的调参候选值组合进行迭代训练。
树的候选值包括5、10、20、40、60、80、100、150、200、400、600、800和1000。
每个树的最大深度候选值包括10、20、40、50、60、70、80、90和100。
我们对每种组合进行了5折交叉验证,并记录每次迭代的性能,使用均方根误差(RMSE)作为衡量指标。
得到最低RMSE值的参数值被用于指定最终模型。
在下一步中应用了该最终模型,并通过将其应用于测试集来报告该模型的拟合优度,作为我们的第一个验证。
利用网格化的协变量作为输入,我们将最终模型应用于每个网格单元,估计出每个网格的加权人口。
接着,我们使用该加权人口将镇级人口分配至每个网格单元。
居住区外的网格单元加权人口被设定为零以避免人口分配。
通过这种分配,镇级的网格人口总和应等于其总人口。
我们对总人口和人口按年龄组(0–14岁、15–59岁、≥60岁和≥65岁)的估算过程分别迭代上述朴素映射过程以获得相应的网格人口估算。
对于每个网格单元,我们将估算的总人口与按年龄组估算的人口之和进行比较。
具体而言,我们计算了两组估计结果之间的相关性和均方根误差,以揭示它们之间的一致性,这是我们的第二个验证。
我们对ASPECT进行了三组验证。首先,我们评估了在镇级上回归人口密度与协变量的拟合优度。
其次,对于每个网格单元,我们比较了估计的总人口与按年龄组估计的总和。
最后,我们使用县级数据实施朴素映射,这对于镇级而言是粗一层的行政级别。
我们根据县级人口数据对所产生的网格人口进行快速汇总,并与实际镇级人口进行比较。
这表明,估算的镇级人口与实际人口相当吻合,R²介于0.61到0.84之间,RMSE介于1000到19000人,具体依赖于人口组。
所有回归系数均低于1,这表明朴素映射在更为密集的人口区域存在低估现象,尤其是0-14岁之间的人口。
在按城市规模划分的情况下,更大规模的城市在估算其总人口和0-14岁及15-59岁人口时,估算值与实际镇级值之间展现更强的相关性,R²表现尤为明显。
然而,镇级人口中年龄分别在60–64岁和≥65岁的人口较小的城市中的预测精度则更高。
考虑到ASPECT是采用镇级数据生成的,因此其准确性可能高于通过县级数据构建的网格数据集。
此外,我们还评估了WorldPop,这是一种广泛采用的精确人口图,亦具备按年龄组区分的估计,以此证明ASPECT的优势。
我们使用了WorldPop的两种2020年数据版本:第一版本是2000–2020版本(与联合国人口统计总数一致),这是目前最新的最终发布版本。
第二版本是正在更新中的2015–2030版本(发布R2024B V1)。
我们进行的两项评估是,首先是评估WorldPop的人口估算与2020年镇级普查人口的匹配程度。
其次,我们评估了WorldPop和ASPECT在估算人口年龄构成(例如65岁及以上人口比例)时所反映的空间变化。
在第一次评估中,与ASPECT使用县级数据推算的人口估算相较,WorldPop(版本2000–2020)可能表现出更大的误差在镇级人口预测上。
具体而言,我们发现WorldPop(2000–2020)的R²在0.41到0.63之间,与2020年普查在镇级的RMSE在1500到28000人之间。
这种预估值的相对一致性显著低于我们使用ASPECT产生的从县级数据获得的估算。
WorldPop(版本2015–2030,发布R2024B V1)在预测镇级人口时表现出更好的性能,R²介于0.56和0.86之间,RMSE在1300到16500人之间。
这表明,当与通过县级数据生成的ASPECT所得结论相比较时,WorldPop的地理分布特征或许能更趋近分层。
注意到,ASPECT由于使用了镇级数据,可能会比WorldPop(2015–2030版)在估算精细化网格人口计数上,更具优势。
我们的第二次评估表明,ASPECT与WorldPop相比,展示的65岁及以上各年龄组所占比重的空间变化更大。
与ASPECT相对比,这种空间变化在WorldPop的年龄结构估计中较少表现出来。
当通过镇级汇总时,WorldPop的年龄结构估计表现出较有限的空间变化。
然而,在给定的空间范围(如省、城市、县或镇)中,WorldPop的空间变化仅为ASPECT的2%到30%之间。
这说明,ASPECT所展现的年龄结构估算的空间变化更为显著。
这表明ASPECT通过对人口进行逐步朴素映射,为不同年龄组进行了多次估算。
而WorldPop中的估算则出现更低的空间变化并显得被截断。这很可能是因为WorldPop通过将县级年龄结构乘以网格总人口来估算不同年龄组的人口。
因此,同一县内的网格单元在特定年龄组上可能共享相同的人口比例。
我们也对ASPECT与Chen等人提出的PopSE进行了比较,后者使用了2020年普查的镇级和县级数据的混合,估算网格人口分布。
具体而言,PopSE使用了15564个镇的样本与所有县进行朴素映射,所代表的是迄今为止最大规模的对2020年普查镇级数据的使用。
而ASPECT不仅对网格级估算总人口进行估算,更按四个年龄组(0–14岁,15–59岁,60–64岁,≥65岁)分层人口分配。
此外,ASPECT还选择了更多的镇(共计40718个镇)用于进行朴素映射,这种精细化的源数据可能会更好地捕捉到人口分布的空间变化,至少在镇级之间如此。
图片源于:nature